If you remember this sound, I'll tell you that I was listening to Youssou Ndour while hacking some Lua on my computer, and was listening to this track, And heard that familiar sound that made me alt-tab to some messaging application (which I don't have anymore).
The muscle memory reaction made me find which was the app, and yes, it's damn msn.
jueves, 28 de diciembre de 2017
lunes, 4 de diciembre de 2017
New-old books for thinking about thinking
So here there are the 4 books I recently got that are keeping me *very* entertained.

Two of them are Lisp-related, and two of them are Hofstadter's.

Two of them are Lisp-related, and two of them are Hofstadter's.
- The minds I : Short stories from Hofstadter, Dennet, and other sci-fi authors and thinkers. I discovered Stanislaw Lem (author of the story 'The Congress' is inspired on). The whole book is mindblowing. 75% read so far.
- Fluid Concepts and Creative Analogies. Another Hofstadter's book. It goes deep in his view of what AI means, and the different phases where a human brain is creating something from nothing. Example: The sense of 50*10 being "easier" than 74*18: which are the reasons why we find that happening? Can we make machines think in that way also? Is it worth it? 40% read so far.
- Partial Evaluation and Automatic Program Generation: I've been wanting to read that book for ages, and it's free in pdf. The phisical copies are astronomically expensive, but I was lucky enough that my book bot found a copy for 3 euros :). It uses crazy techniques to turn interpreters into compiler generators. Futamura projections are totally mindbending. 20% read so far.

- Building Problem Solvers: A Lisp book on problem solvers. I discovered this techniques in Norvig's PAIP, and also CTM has some parts of Constraint Programming, and I thought that was pretty cool and broad, so I got that one also. The book is written in "pre-common" Lisp, so no CLOS, and *lots* of mutable state, setf-ing function arguments and the like. I'm just starting it, but I think it will be more valuable method-wise than code-wise.

viernes, 10 de noviembre de 2017
asm and reverse engineering
I've been lately giving a shot to some assembler tutorials. Just because.
I never did any serious assembler, but when I was into reversing I was eating asm for breakfast, but from the read perspective.
In https://github.com/kidd/assembler-tutorials there are the few codes I wrote, either following tutorials, or walking random paths myself, using nasmx macros.
In windows, there's MASM and NASM, but MASM is not in GNU/Linux, so the option was NASM. It's nice that it gives me the same syntax I was used to in the old days using W32Dasm, ollydbg, soft-ice and friends.
Anyway, I've been looking at nasmX, which are a bunch of macros that lift assembler a bit. At least, allowing you to write with ifs, whiles, and "forgetting" about the calling conventions. Super cool!
Meanwhile, I've been also following some reverse engineering forums, and rediscovered RE a bit. A nice fuzzy feeling that many things are the same, but tooling changed (radare2 is a must in linux, and the learning curve is vim-like). Still, I'm starting to do my first hacks on android using anbox, apktool, and jd. very basic stuff, but nopping a few things and rerunning them in the mobile is already an achievement!
As always, lots of resources, and not so much time to swallow them.
I never did any serious assembler, but when I was into reversing I was eating asm for breakfast, but from the read perspective.
In https://github.com/kidd/assembler-tutorials there are the few codes I wrote, either following tutorials, or walking random paths myself, using nasmx macros.
In windows, there's MASM and NASM, but MASM is not in GNU/Linux, so the option was NASM. It's nice that it gives me the same syntax I was used to in the old days using W32Dasm, ollydbg, soft-ice and friends.
Anyway, I've been looking at nasmX, which are a bunch of macros that lift assembler a bit. At least, allowing you to write with ifs, whiles, and "forgetting" about the calling conventions. Super cool!
Meanwhile, I've been also following some reverse engineering forums, and rediscovered RE a bit. A nice fuzzy feeling that many things are the same, but tooling changed (radare2 is a must in linux, and the learning curve is vim-like). Still, I'm starting to do my first hacks on android using anbox, apktool, and jd. very basic stuff, but nopping a few things and rerunning them in the mobile is already an achievement!
As always, lots of resources, and not so much time to swallow them.
miércoles, 8 de noviembre de 2017
Finally publishing commit-msg-prefix.el
It's been a few months since I released commit-msg-prefix.
Just to remember a bit what was it about, I created a gif so that we all can relate again to it.

The user story is the following:
I just issued the Pull Request for it to be in melpa, so more users can give it a try and I can test it a bit further. I hope it will be accepted and will be available in melpa soon.
Just to remember a bit what was it about, I created a gif so that we all can relate again to it.

The user story is the following:
- In your company/organisation, you have to follow some rule of prefixing all your commits with either a keyword (Add/Remove/Fix/Hotfix/Bump/Release) or an issue number, or something like that.
- When you are about to commit that, you know what you just did (you should!), but you can't remember which particular issue number was that.
- Then you go to jira/trello/github-issues/younameit and look for that and insert it.
Well, commit-msg-prefix makes this automatically for you, so it shows the latest commits (filtered as you want), and lets you choose one (find-as-you-type provided by helm/ivy/ido), and inserts the first word of the commit.
Obviously, most of the relevant settings are configurable, so you can have support for fancier substitutions, or use mercurial logs.
The package itself is pretty simple, but it might be useful to others, and if it is, I'm happy to share it.
I just issued the Pull Request for it to be in melpa, so more users can give it a try and I can test it a bit further. I hope it will be accepted and will be available in melpa soon.
In the future, if it has some adoption, it might make sense to merge it into magit, but I don't want to bother magintainers when the idea is not widely tested yet.
Happy hacking!
martes, 7 de noviembre de 2017
So,... Here's Ivan Sutherland blowing your mind
Just by chance I stumbled upon an Ivan Sutherland's talk. And Listening to this guy is an enlightening experience.
The pace of his talk is calm but not slow, concrete but not obvious, and man.... he talks about history that he's lived in his own self.
For those who do not know who's Ivan Sutherland, he's the guy who invented sketchpad, where many of the concepts that today we give for granted, and some that we're just starting to develop now (most of it in the early sixties). Here's the link to the sketchpad thesis, in case you want to read about it.
Btw, thesis supervisor: Claude E. Shannon.
Here's the talk. Give it a shot. Insight level: "Alan Kay".
The pace of his talk is calm but not slow, concrete but not obvious, and man.... he talks about history that he's lived in his own self.
For those who do not know who's Ivan Sutherland, he's the guy who invented sketchpad, where many of the concepts that today we give for granted, and some that we're just starting to develop now (most of it in the early sixties). Here's the link to the sketchpad thesis, in case you want to read about it.
Btw, thesis supervisor: Claude E. Shannon.
Here's the talk. Give it a shot. Insight level: "Alan Kay".
miércoles, 18 de octubre de 2017
rust + emacs = remacs
I've lately being collaborating a bit with the Remacs project, which attempts to bring Rust to emacs by porting the C parts of emacs. Here's the latest remacs report, by Wilfred, the creator of remacs.
If you love emacs and want to learn Rust, there's enough low hanging fruit in the project that makes a good place to start learning both the emacs internals and also rust (Which is not a simple language IMHO).
Remacs comunity is small, but quite helpful, and many things are still being figured out as migration of different parts take place.
I've personally have contributed with ports of a handful of functions (point and buffer related). Not a lot, but few steps to bring me closer to Rust and emacs at the same time.
From time to time, there's the issue raised about "what benefit do I get by using remacs instead of gnu emacs" or, "Should you try remacs?" I honestly don't know. If you don't have any interest in emacs internals and you don't usually compile your own emacs you won't gain much with remacs. Projectwise, I don't know how gnu emacs will benefit from remacs.
Another question that raises is "if (how) gnu emacs benfits from the contributions on remacs?". Not being a hostile fork but just a fork to experiment with different technologies at a different pace than gnu emacs, remacs is allowed to try different approaches to solving some problems. Support for very old platforms has been dropped, and the idea is to use crates (Rust libraries) for some things that emacs writes ad-hoc (json, md5, regex...).
For now, there's just a tiny fraction of users that use remacs, so it's way too early to think about any impact it may have to mainline gnu emacs.
And on the question: Aren't we moving to guilemacs? Why are you not investing your time on that? ..... For my personal case, I'll say that the low hanging fruit in guilemacs are over my skills. Not so for remacs, where I can chip in and merge my small PR's. Also, github (it's sad, but that's how it is) makes it easier for me to collaborate.
But I get you: The idea of guilemacs is very cool. You know what's also super cool? El compilador. But I don't know, I feel I'm unable to move any of those any forward, and they are still experimental.
[OFFTOPIC: I'm looking for projects where to collaborate. If you have any proposal drop me a line @ raimonster@gmail.com, and we can talk about it. Learning, experience, impact, fun and remote are my metrics nowadays ]
If you love emacs and want to learn Rust, there's enough low hanging fruit in the project that makes a good place to start learning both the emacs internals and also rust (Which is not a simple language IMHO).
Remacs comunity is small, but quite helpful, and many things are still being figured out as migration of different parts take place.
I've personally have contributed with ports of a handful of functions (point and buffer related). Not a lot, but few steps to bring me closer to Rust and emacs at the same time.
From time to time, there's the issue raised about "what benefit do I get by using remacs instead of gnu emacs" or, "Should you try remacs?" I honestly don't know. If you don't have any interest in emacs internals and you don't usually compile your own emacs you won't gain much with remacs. Projectwise, I don't know how gnu emacs will benefit from remacs.
Another question that raises is "if (how) gnu emacs benfits from the contributions on remacs?". Not being a hostile fork but just a fork to experiment with different technologies at a different pace than gnu emacs, remacs is allowed to try different approaches to solving some problems. Support for very old platforms has been dropped, and the idea is to use crates (Rust libraries) for some things that emacs writes ad-hoc (json, md5, regex...).
For now, there's just a tiny fraction of users that use remacs, so it's way too early to think about any impact it may have to mainline gnu emacs.
And on the question: Aren't we moving to guilemacs? Why are you not investing your time on that? ..... For my personal case, I'll say that the low hanging fruit in guilemacs are over my skills. Not so for remacs, where I can chip in and merge my small PR's. Also, github (it's sad, but that's how it is) makes it easier for me to collaborate.
But I get you: The idea of guilemacs is very cool. You know what's also super cool? El compilador. But I don't know, I feel I'm unable to move any of those any forward, and they are still experimental.
[OFFTOPIC: I'm looking for projects where to collaborate. If you have any proposal drop me a line @ raimonster@gmail.com, and we can talk about it. Learning, experience, impact, fun and remote are my metrics nowadays ]
martes, 10 de octubre de 2017
How to Develop a Perfect Memory

Another 'mind hack' book. The original book from Dominic O'Brien (memory champion) where it explains his dominic system and gives tricks and hints on how to apply it to several domains.
It's nice that most of the chapters and tricks use the same core rules, where you have to initially memorize 100 people by their initials, and associate 100 actions to each one of these people. Then you create funny images on a chain of known places using people and the actions.
I've read it and for now I'm only applying to raw memorization of numbers, like phone numbers, credit card numbers and time schedules for buses and trains.
Those techniques are quite useful, and honestly, not hard to use (at least, getting to the "ok plateau"), but I find that this doesn't help much when remembering APIS, or complex entangled fuzzy concepts. Now I'm reading this fuzzy logic, and also I'm continuing "Exploring the world of lucid dreaming", that I started long time ago, in another of my regular rampages of self-hacking I had many years ago.
lunes, 25 de septiembre de 2017
jueves, 14 de septiembre de 2017
Moonwalking with Einstein

Long time ago (around 2008) I read an oreilly book called Mind Hacks, which teached some techniques to 'overclock' one's memory, or recall, or mental arithmetic. I remembered the "1 is a bun, 2 is a shoe" placeholders, but here I learned about PAO, the major system and the Dominic System, to be able to remember random numbers (I now know my credit card by heart, after all those years).
I'm now working on my own PAO list (I'm using a mixture of Dominic System and arbitrary associations), and I hope to get to some decent proficency of memorization of numbers and tasks using the technique of loci.
A chapter on Savants, mentioning Brainman (highly recommended), and references to Tony Buzan and random folklore from the 90's make it a very enjoyable fast read.
Overall I liked the book quite a lot, it was fun to read, and I definitely got something from it. I'm afraid none of these techniques used by Memory Athlets will be very useful to retain the kind of information I usually need to remember like programming APIs, data from books (like memorization techniques, heh), or some data that needs to have more context than just a random number.
Anyway, I'm convinced already that the fact that converting things to vivid images and placing them in a memory palace greatly improves recalling.
Next stop, How to develop a perfect memory. And I think that will be enough for this streak of self-improvement.
lunes, 11 de septiembre de 2017
Xamarin on linux
So the whole thing starts wanting to try Xamarin, for a meetup I'm going next Saturday.
The story goes in the following way:
The story goes in the following way:
- download and install VirtualBox
- get some Windows CD/iso. (Windows 7 in my case, to make it the least bloated)
- Install windows7 in a Virtualbox.
- Realize that you have no space left because Windows needs about 16Gb
- Remove some files from my hard drive until I have 25 free Gb. Not very happy to do that.
- Install windows7 in a Virtualbox with a 25Gb hd ".vdi" file.
- Try to store the vdi file in a usb drive so at least I have a quick backup to restore from.
- Realize I can't move 4Gb+ files to my usb drive because it's vfat (because windows compatibility)
- /shrug and think "it will be fine" no backup
- Get visual studio comunity edition.
- Try to install it....
- wait
- wait
- wait
- Install xamarin & android sdk from the installer.
- Fuck, it needs 8Gb+, and I don't have them available.
- Try to increase the hdd volume. The instructions are scary. And for windows hosts.
- cold sweat
- Share a folder with the guest OS.
- Can't install software there.
- Flip table
- Realize I don't want to have anything to do with a system that requires 30Gb+ of bloat to write a single hello world. That I cannot ever move from my hd because it doesn't survive in a vfat hd (that I have in this format ONLY to make it compatible with windows)
- Remove the whole crap.
- Go learn something useful and fun. It's not that there're no candidates (Rust, Clojure, Reverse Engineering, MachineLearning....)
viernes, 1 de septiembre de 2017
Birds of a feather lisp together
Now that I have some time in my hands (and I already mis Lisp), I'm watching several old Lisp talks, and stumbled upon This event.
On December 3 and 4 of 2004, the Computer Science Department at Indiana University hosted this conference on the occasion of Dan's sixtieth birthday.
Guy Steele's talk is great, as always. Nothing surprising there. Talking about Dan's ideas and Dan itself (and giving a feeling about Dan being isomorphic to what Gilad Bracha says about Luca Cardelli here).
Gerald J Sussman's talk is also very nice, again, as usual.
And all talks I saw have that lispy emotion that we love.
But something that stroke me the most (that after reading 'The information' I realize more) was when Guy Steele talks about the time he read a draft of GEB. It's also a warm fuzzy feeling. Reading GEB leaves some trace in the reader forever. You never read a book the same way, or look at reality in the same way. Same happens with SICP (in process analysis).
Then I realized that in the picture of the event, there are the 3 of them. gls, gjs, and Douglas Hofstadter. Because obviously, they are "friends". And the realization that the authors of my 2 favourite books ever hang around sometimes.
I also remember some Alan Kay talk where he says something like: "a few hours ago I found Guy Steele in a corridor in this event and we talked about blablabla.....". 100% natural :)
Then, while researching a bit for this post, I browsed wikipedia for Hofstadter. And another "proof" that "among certain level of smartness, there's just 1 degree of separation between any two people".
[...]he organized a larger symposium entitled "Spiritual Robots" at Stanford University, in which he moderated a panel consisting of Ray Kurzweil, Hans Moravec, Kevin Kelly, Ralph Merkle, Bill Joy, Frank Drake, John Holland and John Koza.
On December 3 and 4 of 2004, the Computer Science Department at Indiana University hosted this conference on the occasion of Dan's sixtieth birthday.
Guy Steele's talk is great, as always. Nothing surprising there. Talking about Dan's ideas and Dan itself (and giving a feeling about Dan being isomorphic to what Gilad Bracha says about Luca Cardelli here).
Gerald J Sussman's talk is also very nice, again, as usual.
And all talks I saw have that lispy emotion that we love.
But something that stroke me the most (that after reading 'The information' I realize more) was when Guy Steele talks about the time he read a draft of GEB. It's also a warm fuzzy feeling. Reading GEB leaves some trace in the reader forever. You never read a book the same way, or look at reality in the same way. Same happens with SICP (in process analysis).
Then I realized that in the picture of the event, there are the 3 of them. gls, gjs, and Douglas Hofstadter. Because obviously, they are "friends". And the realization that the authors of my 2 favourite books ever hang around sometimes.
I also remember some Alan Kay talk where he says something like: "a few hours ago I found Guy Steele in a corridor in this event and we talked about blablabla.....". 100% natural :)
Then, while researching a bit for this post, I browsed wikipedia for Hofstadter. And another "proof" that "among certain level of smartness, there's just 1 degree of separation between any two people".
[...]he organized a larger symposium entitled "Spiritual Robots" at Stanford University, in which he moderated a panel consisting of Ray Kurzweil, Hans Moravec, Kevin Kelly, Ralph Merkle, Bill Joy, Frank Drake, John Holland and John Koza.
jueves, 31 de agosto de 2017
Everyone welcome Wilfred to the emacs hall of fame.
The recent emacs' hall of fame: Magnars, Malabarba, abo-abo..... and now, we have Wilfred Hughes.
Thank you all for inspiring us, each one with different styles, influences and strategies. Kudos!
Thank you all for inspiring us, each one with different styles, influences and strategies. Kudos!
jueves, 17 de agosto de 2017
grep for two words in the same file
Let's go for some more csv (or any text file) fixing, grepping and slicing and dicing.
The problem is simple:
Find a file (among a vast amount of them) that contains 2 or more words, not necessarily in the same line.
That makes piping greps onto other greps useless. The solution is quite easy, but it might not be obvious:
Thanks for watching.
The problem is simple:
Find a file (among a vast amount of them) that contains 2 or more words, not necessarily in the same line.
That makes piping greps onto other greps useless. The solution is quite easy, but it might not be obvious:
grep -l word1 **/*csv(.) | xargs grep -l word2
Thanks for watching.
miércoles, 16 de agosto de 2017
guerrilla csv and xlsx
I like to have a huge toolbox so that I can always find the right tool to do any task. But I'm also a big fan of composability, and orthogonality. So it's a bit like vim vs emacs, or small languages vs big languages, or scheme vs CL, or Python vs Perl.
On the command line, I also like to find tools that compose. Although pipes and xargs are the way to compose commands, the interfaces have to be compatble, by using stdin/stdout, or file names ( <() comes to the rescue by helping with the plumbing).
So today I had to count the appearances of a given word in different xlsx files. Each xlsx had many sheets, and we only want to count the appearances in column 9. It was kind of a checksum to make sure that all appearances of $KEYWORD were still there. So, task the task is:
Aggregate counts of appearances of 'keyword' in the ninth column in all sheets of each one of those excels. Get the sum per file.
Apparently, after 5 minutes of typing in trance, this did the trick.
We can't get much further with debugging this. The pity with these kind of approaches is that they either solve your problem in the first shoot, or it gets exponentially difficult to treat for special cases, or add debugging info.
I got to, at least, compare the results themselves using vimdiff.
This is totally not rocket science, but I love the feeling of power and accomplishment you get when this magic incantations work. You run that, you get the result, you use the result, and you throw the whole thing away.
And you keep doing what you were doing. Or go write a post about that.
On the command line, I also like to find tools that compose. Although pipes and xargs are the way to compose commands, the interfaces have to be compatble, by using stdin/stdout, or file names ( <() comes to the rescue by helping with the plumbing).
So today I had to count the appearances of a given word in different xlsx files. Each xlsx had many sheets, and we only want to count the appearances in column 9. It was kind of a checksum to make sure that all appearances of $KEYWORD were still there. So, task the task is:
Aggregate counts of appearances of 'keyword' in the ninth column in all sheets of each one of those excels. Get the sum per file.
Apparently, after 5 minutes of typing in trance, this did the trick.
for i in **/*xlsx ; do echo $i ; csvfix write_dsv -f 9 <(xlsx2csv.py --all $i ) G 'keyword' WC ; done
We can't get much further with debugging this. The pity with these kind of approaches is that they either solve your problem in the first shoot, or it gets exponentially difficult to treat for special cases, or add debugging info.
I got to, at least, compare the results themselves using vimdiff.
vimdiff <(csvfix write_dsv -f 9 <(xlsx2csv.py --all file1.xlsx ) G 'keyword') \
<(csvfix write_dsv -f 9 <(xlsx2csv.py --all file2.xlsx ) G 'keyword')
This is totally not rocket science, but I love the feeling of power and accomplishment you get when this magic incantations work. You run that, you get the result, you use the result, and you throw the whole thing away.
And you keep doing what you were doing. Or go write a post about that.
domingo, 13 de agosto de 2017
The information

I've just finished one of the books I've enjoyed the most. In my life. "The Information", by James Gleick. I'm totally fascinated by it. maybe because of many references I already knew, and it added contents here and there to a field I'm already into it. I don't know, it's a different beast from purely original content books, as this one is mostly a recap of stories and history, but it's put in a VERY enjoyful way. It burnt my pan twice.
It was a recommendation from Santiago Ortiz, and it was a blast. Filled with insights and anecdotes about how mankind have been treating the information (or the lack of), storing, understanding, using, creating, inventing, discovering.....
I'd say it's a more practical (and up to date) companion for Thomas Khun's "the structure of scientific revolutions". It's nowhere near as revolutionary, but I found it a great source of epistemology.
If you've read CODE by Charles Petzold, I'd say it drives you so a similar steep ramp, but in the abstract side of the same concepts. From simple to complex, from individuality to community, from concrete to abstract, from singularity to commonality. Layers of abstraction get placed one after the other, using bricks filled with dates, names and anecdotes.
It quotes the masters, and it's filled with folklore, which helps you understand what happened when. I truly enjoyed it, and I have tenths of bookmarks inside it, which means I had tenths of AHA! moments. Which unfortunately doesn't happen very often.
martes, 8 de agosto de 2017
Dynamic Languages Wizards Series - Panel on Language Design
This video is a stream of knowledge and insights capsules from VERY smart people related to dynamic languages. Give it a try. 0 bullshit.
miércoles, 12 de julio de 2017
TIL: insert key in kinesis advantage
I found this in the kinesis FAQ.
How can I remap the embedded Insert key to the top layer, so it’s like my older keyboard? 1). Turn Keypad On. 2). Press and hold the Progrm key and tap F12 (LED’s on keyboard will flash rapidly). 3). Press and release the “Insert” key (LED’s will slow down). 4). Press and release the Keypad key. 5). Press and release the Insert key again (LED’s will speed up). 6). Exit by repeating step 2 (LED’s will stop flashing).
miércoles, 5 de julio de 2017
TIL: awk > grep
Well, I already knew that awk > grep, but what I learned today is this little trick of "regex over a single field":
cat file.tsv | awk '$1 ~ /-01$/'foo-01 bar domingo, 2 de julio de 2017
Announcing commit-msg-prefix.
When writing commit messages, it's usual that your company/organisation has some policies and rules about the format and contents in the messages.
Some use an issue number, or name, or start with keywords (or emojis) like Add:/Clean:/Remove:.. (that can be converted to emojis in emacs too). But it's clear that somehow there's value in some kind of standarization.
So I created commit-msg-prefix, which lists the previous git commit messages and lets you pick one of them, and it will insert the relevant part of the commit in your current buffer.
My use case is when I do not remember the issue name/number I'm working on, but I remember keywords of previous commits that belong to the same issue.
There are a few variables to configure, like the exact git (or other) command to fetch logs, and the regex to apply to the log to extract the relevant part to insert.
The variable "commit-msg-prefix-input-method" is one of the symbols ('completing-read 'ido-completing-read 'commit-msg-prefix-helm-read 'ivy-read).
it defaults to ido-completing-read, but the idea is that you use your favourite input method. ivy or helm, I guess :)
Some use an issue number, or name, or start with keywords (or emojis) like Add:/Clean:/Remove:.. (that can be converted to emojis in emacs too). But it's clear that somehow there's value in some kind of standarization.
So I created commit-msg-prefix, which lists the previous git commit messages and lets you pick one of them, and it will insert the relevant part of the commit in your current buffer.
My use case is when I do not remember the issue name/number I'm working on, but I remember keywords of previous commits that belong to the same issue.
There are a few variables to configure, like the exact git (or other) command to fetch logs, and the regex to apply to the log to extract the relevant part to insert.
The variable "commit-msg-prefix-input-method" is one of the symbols ('completing-read 'ido-completing-read 'commit-msg-prefix-helm-read 'ivy-read).
it defaults to ido-completing-read, but the idea is that you use your favourite input method. ivy or helm, I guess :)
martes, 27 de junio de 2017
Articles on transducers
Some time ago I wrote about recusion and the Y combinator. It is a nice mind puzzle to try to understand all those constructions and techniques. I also linked to a recursion-to-iteration series that was very deep in the subject.
Today, I'm comming with a copule of links to recusion, but also transducers .
If you haven't had enough, another great Eli's post about computed gotos. It talks about how gotos are faster than a switch-case statement for a tight dispatch table. Aaron Patterson has a great talk about things like this at a higher level called something like "what's in a method" or something like this. Google it for more info.
Today, I'm comming with a copule of links to recusion, but also transducers .
If you haven't had enough, another great Eli's post about computed gotos. It talks about how gotos are faster than a switch-case statement for a tight dispatch table. Aaron Patterson has a great talk about things like this at a higher level called something like "what's in a method" or something like this. Google it for more info.
lunes, 19 de junio de 2017
TIL: evil-buffer-regexps
So I have my evil-mode perfectly adapted to my workflow, activating or deactivating it by default depending on the major-mode, so that I don't get into normal mode on magit buffers, or sly-*, or eww.
BUT, there are some buffers which you cannot easily control, because they reuse some major mode where I usually want evil-normal, but not in those cases.
In my case, it's *sly-macroexpansion* and *sly-description* buffers. They are both "lisp-mode" buffers (for syntax highlighting purposes and such), but I want 'q' to quit them. As they do not represent any file, I was out of luck binding modes to file extensions. (btw, here's some recent article talking bout the ways emacs chooses your major mode)
So trying to hack something using emacs hooks, I found that, in fact, evil has us covered, and provides a evil-buffer-regexps, that allows us to predefine modes on given buffer names.
BUT, there are some buffers which you cannot easily control, because they reuse some major mode where I usually want evil-normal, but not in those cases.
In my case, it's *sly-macroexpansion* and *sly-description* buffers. They are both "lisp-mode" buffers (for syntax highlighting purposes and such), but I want 'q' to quit them. As they do not represent any file, I was out of luck binding modes to file extensions. (btw, here's some recent article talking bout the ways emacs chooses your major mode)
So trying to hack something using emacs hooks, I found that, in fact, evil has us covered, and provides a evil-buffer-regexps, that allows us to predefine modes on given buffer names.
(add-to-list 'evil-buffer-regexps
'("\\*sly-macroexpansion\\*" . emacs))
miércoles, 14 de junio de 2017
Visualisation, patterns, and perspecives
This all started a couple of weeks ago in the J on the Beach conference, where I was in a talk by Santiago Ortiz, which was VERY inspirational to me.
He was talking about the infinite forms of visualizing information (with nice examples about "ways to represent the concept 75". It might seem a very stupid exercise, but it was very interesting to see way many more representations that I was expecting to see.)
Days passed, and I kept thinking about visualization of stuff via alternative and non usual ways. The fact that I'm reading "The Mind's I"(Hofstadter & Dennet) helped to keep thinking about Alan Kay, Seymour Papert, Douglas Hofstadter, who in one way or another they always look at things in ways that are different to what a normal layman would look at them, and they make connections at a cognitive level that other (we) can only grasp after-fact, and when we are spoon fed.
Something like tihs happened to me on that talk. Concepts that weren't totally alien to me ("a point of view is worth 80 IQ", creating a callgraph as it executes to learn about memoizing), were made obvious when that guy was explaining them in a very vivid and enthusiastic way. Big kudos.
I've been always a fan of all kind of puzzles, and mind hacks (I still remember that 'Mind Hacks' OReilly book). The talk also had some mnemotechnic tips and tricks. Another +1.
So, fast forward 3 weeks, and I already have this dupplot repo where you can display code duplication as a dotplot. Very nice and handy :).
So today at work, my colleague Carlos passed me this article about using your visual capabilities as a computing engine. A total mindfuck. check it out.
And this evening I've been looking for David Waltz's interpreting line drawings that I discovered in an excelent talk by Gerald Sussman. This line labeling makes a lot of sense when you think about it, and it's dead easy to get.
I still wanted to talk about smalltalk tools for visualizing and reasoning about code. And about data ingestion growing linearly, while insight grows discontinuously, because it's from connections between nodes that people understand behaviours andget value from it.
Also, one of the games Santiago Ortiz did was about remembering triplets of (person, action, place) for every number from 0 to 99. Then, when you have to remember say, 6 digits, you group them by chunks of 2, and group those grouped numbers by 3. After that, you may remember a scene that is about the person that refers to the first 2 digits, doing the action of te second 2 digits, in the place ment by the third 2 digits. Messi exploding the Moon was 104569. Amazing how these things work so well. :)
Gracias!
He was talking about the infinite forms of visualizing information (with nice examples about "ways to represent the concept 75". It might seem a very stupid exercise, but it was very interesting to see way many more representations that I was expecting to see.)
Days passed, and I kept thinking about visualization of stuff via alternative and non usual ways. The fact that I'm reading "The Mind's I"(Hofstadter & Dennet) helped to keep thinking about Alan Kay, Seymour Papert, Douglas Hofstadter, who in one way or another they always look at things in ways that are different to what a normal layman would look at them, and they make connections at a cognitive level that other (we) can only grasp after-fact, and when we are spoon fed.
Something like tihs happened to me on that talk. Concepts that weren't totally alien to me ("a point of view is worth 80 IQ", creating a callgraph as it executes to learn about memoizing), were made obvious when that guy was explaining them in a very vivid and enthusiastic way. Big kudos.
I've been always a fan of all kind of puzzles, and mind hacks (I still remember that 'Mind Hacks' OReilly book). The talk also had some mnemotechnic tips and tricks. Another +1.
So, fast forward 3 weeks, and I already have this dupplot repo where you can display code duplication as a dotplot. Very nice and handy :).
So today at work, my colleague Carlos passed me this article about using your visual capabilities as a computing engine. A total mindfuck. check it out.
And this evening I've been looking for David Waltz's interpreting line drawings that I discovered in an excelent talk by Gerald Sussman. This line labeling makes a lot of sense when you think about it, and it's dead easy to get.
I still wanted to talk about smalltalk tools for visualizing and reasoning about code. And about data ingestion growing linearly, while insight grows discontinuously, because it's from connections between nodes that people understand behaviours andget value from it.
Also, one of the games Santiago Ortiz did was about remembering triplets of (person, action, place) for every number from 0 to 99. Then, when you have to remember say, 6 digits, you group them by chunks of 2, and group those grouped numbers by 3. After that, you may remember a scene that is about the person that refers to the first 2 digits, doing the action of te second 2 digits, in the place ment by the third 2 digits. Messi exploding the Moon was 104569. Amazing how these things work so well. :)
Gracias!
lunes, 12 de junio de 2017
Visualizing code duplication as dot plots
Lately I've been having to deal with some codebase which I suspected
it had lots of duplicated code.
My task was actually fix some parts of the application, cleanup the
some of the parts, and end up owning the code as mine.
So it was a perfect opportunity for me to give a serious thougth to
Object Oriented Reengineering Patterns , refactoring, and Working with
legacy code. I started with OORP, because it's the less widely
known about all three, and I thought maybe there would be advice
that's not widely covered on other places in the internet.
Among other advices (and related to other works in the smalltalk
world), there's the thougth about trying to look at the code in
different ways, not the obvious 'lines of text'.
So here's dupplot, a small script I wrote to visualize code
duplication through dotplots.
While working with dupplot itself, I started pushing lines of code,
to make it work the first time. And then, I was thinking that I had
some code duplication (opening the file, normalizing lines,etc.) but
it was generally ok-ish.
Just for the sake of testing the program against itself, I ran it, and got this:

So I thought that I'd try to fix some of the duplication, and yeah,
now it looks much better.

Much much nicer, no? Both codes are available in https://github.com/kidd/dupplot, as dupplot.pl and dupplot2.pl.
it had lots of duplicated code.
My task was actually fix some parts of the application, cleanup the
some of the parts, and end up owning the code as mine.
So it was a perfect opportunity for me to give a serious thougth to
legacy code. I started with OORP, because it's the less widely
known about all three, and I thought maybe there would be advice
that's not widely covered on other places in the internet.
Among other advices (and related to other works in the smalltalk
world), there's the thougth about trying to look at the code in
different ways, not the obvious 'lines of text'.
So here's dupplot, a small script I wrote to visualize code
duplication through dotplots.
While working with dupplot itself, I started pushing lines of code,
to make it work the first time. And then, I was thinking that I had
some code duplication (opening the file, normalizing lines,etc.) but
it was generally ok-ish.
Just for the sake of testing the program against itself, I ran it, and got this:
So I thought that I'd try to fix some of the duplication, and yeah,
now it looks much better.
Much much nicer, no? Both codes are available in https://github.com/kidd/dupplot, as dupplot.pl and dupplot2.pl.
martes, 6 de junio de 2017
scripting your .ssh/config with scheme
Generating config files via programs is an old trick which I'm not going to rediscover now. But this one is my first scheme script I wrote for that purpose.
It's about generating a config file you ought to put in your ~/.ssh/config , so that there are some sane defaults when you are ssh-ing to your servers.
It's using the amazon cli interface to fetch the instances of your aws infrastructure. Then, concatenating it with a list of custome servers, and that's basically it (I'm using chicken scheme here, with the regex module which you can get via chicken-install):
With just this, you can already ssh to the servers and have your username filled in, or have your aliases in there.
Also, as I'm super super lazy, I also have a readily available command to prompt me for the server I want to ssh to, and make it ssh there. Quite simple stuff, but hey, it works :)
It's about generating a config file you ought to put in your ~/.ssh/config , so that there are some sane defaults when you are ssh-ing to your servers.
It's using the amazon cli interface to fetch the instances of your aws infrastructure. Then, concatenating it with a list of custome servers, and that's basically it (I'm using chicken scheme here, with the regex module which you can get via chicken-install):
With just this, you can already ssh to the servers and have your username filled in, or have your aliases in there.
Also, as I'm super super lazy, I also have a readily available command to prompt me for the server I want to ssh to, and make it ssh there. Quite simple stuff, but hey, it works :)
urxvt -e ssh $(grep 'host ' .ssh/config | awk '{print $2}' | dmenu -l 10)
jueves, 1 de junio de 2017
TIL: pipe postgres output to console
If you use postgres and want to run a query from the console, and react on the output of the console, here are the flags that will make postgres just output the output of the query, without counts or titles, or anything.
In this case, we're not using '-F,' but it would make the output be a CSV, so you could do fancier things here.
In this case I want to check if a user has an active session. You can put it in a cronjob and leave it running for some time.
Yes. there are logs for that .
psql -A -q -h host1 -U user1 -d database1 -p 5439 -c "select count(*) from stv_sessions where user_name = 'usertofind'" -F, -t |
grep "^0$" || send-me-a-mail "we detected usertofind"
In this case, we're not using '-F,' but it would make the output be a CSV, so you could do fancier things here.
In this case I want to check if a user has an active session. You can put it in a cronjob and leave it running for some time.
Yes. there are logs for that .
miércoles, 17 de mayo de 2017
Descarregar programes de RAC1 desde la linea de comandes
Fa anys que sóc seguidor de "La Competència", i no sempre puc escoltarla en directe.
Bé, hi ha la opcio de descarregar programes desde "rac1 a la
carta".
El tema es que es un conyàs anar manualment a la web i descarregar el mp3. Fins aquesta setmana, el següent zsh script m'ha deixat descarregar el mp3 del dia:
Doncs ara resulta que han canviat la web, i m'he hagut de fer un altre script per a descarregar l'últim programa de la competencia
El tema es que es un conyàs anar manualment a la web i descarregar el mp3. Fins aquesta setmana, el següent zsh script m'ha deixat descarregar el mp3 del dia:
function lacomp () {
typeset -A days
days[Sun]=Diumenge
days[dom]=Diumenge
days[Mon]=Dilluns
days[lun]=Dilluns
days[Tue]=Dimarts
days[mar]=Dimarts
days[Wed]=Dimecres
days[mié]=Dimecres
days[Thu]=Dijous
days[jue]=Dijous
days[Fri]=Divendres
days[vie]=Divendres
days[Sat]=Dissabte
days[sab]=Dissabte
#echo $(${days[$(date +%a)]})
echo $(date +%a)
wget "http://www.racalacarta.com/download.php?file=download.php-file=$(date +%m)$(date +%d)%2012h%20(${days[$(date +%a)]}%20$(date +%d-%m-%y))%20%20%20LA%20COMPETENCIA.mp3"
return
}
Doncs ara resulta que han canviat la web, i m'he hagut de fer un altre script per a descarregar l'últim programa de la competencia
function lacompeti () {
curl http://www.rac1.cat/a-la-carta/la-competencia | pup 'a.fa-arrow-down attr{href} ' | head -1 | xargs wget
ls -tr *mp3*download | tail -1 | xargs mplayer
}
jueves, 11 de mayo de 2017
Git 2.13 has been released
As you can see in github blog, there's a new git version (2.13).
There are some internal and some external changes, but the one that stroke me as most useful for me is conditional configurations.
Conditional includes, means that you can preset in your ~/.gitconfig some conditions, like
After that, you'll be able to commit away in any project in your computer, and git will do The Proper Thing. This is just awesome, that all the hackery I had to simulate this can now go away. I'm going to add this to my configs NOW. :)
As this is a git post, I'll take the opportunity to mention this blogpost about filter branch. Also, this one about packfiles. Both are advanced topics, but you know..... it's fun :)
There are some internal and some external changes, but the one that stroke me as most useful for me is conditional configurations.
Conditional includes, means that you can preset in your ~/.gitconfig some conditions, like
[includeIf "gitdir:~/work/"]
path = .gitconfig-work
[includeIf "gitdir:~/play/"]
path = .gitconfig-play $ cat ~/.gitconfig-work
[user]
name = Serious Q. Programmer
email = serious.programmer@business.example.com
$ cat ~/.gitconfig-play
[user]
name = Random J. Hacker
email = rmsfan1979@example.com After that, you'll be able to commit away in any project in your computer, and git will do The Proper Thing. This is just awesome, that all the hackery I had to simulate this can now go away. I'm going to add this to my configs NOW. :)
As this is a git post, I'll take the opportunity to mention this blogpost about filter branch. Also, this one about packfiles. Both are advanced topics, but you know..... it's fun :)
jueves, 27 de abril de 2017
Pipeline arquitectures
Lately I've been developing a real time stream application, that delivers content via http long poll requests.
The details of the inner parts are not important, but overall, you can see it as many other applications, which transform, filter and distribute individual pieces of datastructures. On the macro level, different components are connected via ZMQ or rabbitMQ, or any queuing system you like. Heck, you could use resque/sidekiq for that also.
Inside the components, although I like to use CLOS OOP (for it's inspection capabilities, and sometimes multiple dispatch), there's the idea of pipelines (or streams) which I like very much.
Here are some pointers for this approach I'd like to review:
- Rob Pike talks. I love this one, which tells the difference about concurrency and parallelism. Also go concurrency patterns. I guess this one is also cool, but I haven't actually seen it, it just has a cool name.
- Talk about pipes in OCaml. This one isn't particularly enligthening if you have some knowledge of streams, as in SICP streams, but it gives a vision for functional programmers.
- Anything you find about pipeline arquitecture is ok.
- Thanks to native coroutines, lua provides nice uses and docs for pipelines. Also picolisp has support for coroutines.
- Full on functional. Coroutines for streaming in haskell.
- HighScalability article about disqus architecture.
- Also, using just active objects is a nice approach to, at least split responsabilities, and make the producer-consumer dance work. Kudos to the great CTM book that explains them super nicely.
The details of the inner parts are not important, but overall, you can see it as many other applications, which transform, filter and distribute individual pieces of datastructures. On the macro level, different components are connected via ZMQ or rabbitMQ, or any queuing system you like. Heck, you could use resque/sidekiq for that also.
Inside the components, although I like to use CLOS OOP (for it's inspection capabilities, and sometimes multiple dispatch), there's the idea of pipelines (or streams) which I like very much.
Here are some pointers for this approach I'd like to review:
- Rob Pike talks. I love this one, which tells the difference about concurrency and parallelism. Also go concurrency patterns. I guess this one is also cool, but I haven't actually seen it, it just has a cool name.
- Talk about pipes in OCaml. This one isn't particularly enligthening if you have some knowledge of streams, as in SICP streams, but it gives a vision for functional programmers.
- Anything you find about pipeline arquitecture is ok.
- Thanks to native coroutines, lua provides nice uses and docs for pipelines. Also picolisp has support for coroutines.
- Full on functional. Coroutines for streaming in haskell.
- HighScalability article about disqus architecture.
- Also, using just active objects is a nice approach to, at least split responsabilities, and make the producer-consumer dance work. Kudos to the great CTM book that explains them super nicely.
martes, 25 de abril de 2017
debugging dns with dnsmasq
I'm not specially gifted at debugging network issues, but I try my best, and lately it seems I have to fight networks quite often.
This is how to debug dns queries using dnsmasq. Dnsmasqhas many many flags and options, but with this I could log when requests are done, and their responses, so it gives you an understanding of what's happening under the hood.
dnsmasq -k -q -h -R --server=8.8.8.8 --log-facility=-
Speaking about dns, here's a recent post by spotify, with more than you ever wanted to know about dns :)
This is how to debug dns queries using dnsmasq. Dnsmasqhas many many flags and options, but with this I could log when requests are done, and their responses, so it gives you an understanding of what's happening under the hood.
dnsmasq -k -q -h -R --server=8.8.8.8 --log-facility=-
Speaking about dns, here's a recent post by spotify, with more than you ever wanted to know about dns :)
sábado, 22 de abril de 2017
Tcl, Red, Nim, Spry, Wren and Gravity
On random walks around the internet, I'm always looking for a language that can provide me the easiness of use of shell languages (and pipes, don't forget pipes), but with more flexibility. I'm still using zsh (and trying to sneak picolisp and factor), but here are the new contenders/discoveries.
I found Red, which looked super interesting. Very smalltalkish, and with very good support for windows GUI programming and interacting with the outside world. I haven't done anything beyond the classical "hello worlds", "factorials", "guess number"... It looks very cool though. It probably has 0 libraries, but well, you can't have it all. Refinements look very cool. no idea how they are implemented, but it's a really nice idea.
Tcl, which you usually read that is something like a 'bad joke', because everything is a string. But since I read that antirez's article I think it has something to it.
Nim, is probably the language with more share of all the ones listed here. It's nice and cute, and compiles to native, or js (multiple backends always look cool). Although I'm learning C myself because it's one of the fundamental languages one has to know, nim looks like a useful alternative for more practical purposes. It supports lots of modern idoms (map, filter,.. reduce...) and practices (channels, etc..). And also has support for macros (shown in the link to convert a bf interpreter to a compiler).
Spry, is a language created by Goran Krampe, that smalltalk wizard. It's implemented in Nim, and has ideas from Lisp, Rebol, Forth and Smalltalk. It looks very nice, but it's just a toy for now.
Wren and gravity, both small, with ideas from Lua/smalltalk/erlang.
And in wren performance page, there's this paragraph:
"Tested against Lua 5.2.3, LuaJIT 2.0.2, Python 2.7.5, Python 3.3.4, ruby 2.0.0p247. LuaJIT is run with the JIT disabled (i.e. in bytecode interpreter mode) since I want to support platforms where JIT-compilation is disallowed. LuaJIT with the JIT enabled is much faster than all of the other languages benchmarked, including Wren, because Mike Pall is a robot from the future."
Mike Pall is a robot from the future.
I found Red, which looked super interesting. Very smalltalkish, and with very good support for windows GUI programming and interacting with the outside world. I haven't done anything beyond the classical "hello worlds", "factorials", "guess number"... It looks very cool though. It probably has 0 libraries, but well, you can't have it all. Refinements look very cool. no idea how they are implemented, but it's a really nice idea.
Tcl, which you usually read that is something like a 'bad joke', because everything is a string. But since I read that antirez's article I think it has something to it.
Nim, is probably the language with more share of all the ones listed here. It's nice and cute, and compiles to native, or js (multiple backends always look cool). Although I'm learning C myself because it's one of the fundamental languages one has to know, nim looks like a useful alternative for more practical purposes. It supports lots of modern idoms (map, filter,.. reduce...) and practices (channels, etc..). And also has support for macros (shown in the link to convert a bf interpreter to a compiler).
Spry, is a language created by Goran Krampe, that smalltalk wizard. It's implemented in Nim, and has ideas from Lisp, Rebol, Forth and Smalltalk. It looks very nice, but it's just a toy for now.
Wren and gravity, both small, with ideas from Lua/smalltalk/erlang.
And in wren performance page, there's this paragraph:
"Tested against Lua 5.2.3, LuaJIT 2.0.2, Python 2.7.5, Python 3.3.4, ruby 2.0.0p247. LuaJIT is run with the JIT disabled (i.e. in bytecode interpreter mode) since I want to support platforms where JIT-compilation is disallowed. LuaJIT with the JIT enabled is much faster than all of the other languages benchmarked, including Wren, because Mike Pall is a robot from the future."
Mike Pall is a robot from the future.
jueves, 20 de abril de 2017
Logs, metrics and what to log.
Lately I've had to decide (and give some advice) on logging and metrics. I'm learning a lot as I go, but I think I'm starting to get some kind of grip of what should be what, and on what level.
Here's this link about logs vs metrics, which makes lots of sense.
And also, a post about logging levels, and how a very basic rule serves for it deciding which level means what. Very useful info in the associated reddit thread.
Here's this link about logs vs metrics, which makes lots of sense.
And also, a post about logging levels, and how a very basic rule serves for it deciding which level means what. Very useful info in the associated reddit thread.
- DEBUG: information that is useful during development. Usually very chatty, and will not show in production.
- INFO: information you will need to debug production issues.
- WARN: someone in the team will have to investigate what happened, but it can wait until tomorrow.
- ERROR: Oh-oh, call the fireman! This needs to be investigated now!
miércoles, 19 de abril de 2017
k/Apl info
- APL self hosted compiler https://news.ycombinator.com/item?id=13797797
- APL self hosted compiler screencast https://www.youtube.com/watch?v=gcUWTa16Jc0
- q manual http://code.kx.com/q4m3/
- ok manual https://github.com/JohnEarnest/ok/blob/gh-pages/docs/Manual.md
- k main page http://kparc.com/
- kona https://github.com/kevinlawler/kona
domingo, 16 de abril de 2017
quote a day, some factor code and some bash+pup+jq
For todays hack, I wanted to have some tiny app that would display a quote/sentence/link at random. Basically, the same as the "fortune" unix command.
In principle it should be trivial, it's just picking a random quote from a huge file.
The idea of doing it in factor was, well... to be able to do anything at all in factor, as most of my previous attempts failed to produce anything that even did what I expected. The tiny repo is in github.
In principle it should be trivial, it's just picking a random quote from a huge file.
The idea of doing it in factor was, well... to be able to do anything at all in factor, as most of my previous attempts failed to produce anything that even did what I expected. The tiny repo is in github.
What made Xerox PARC so special?
Via Hacker News, I found this cool answer by Alan Kay about "What made Xerox PARC so special?"
Very nice, and I got a couple of book references I'm already pushing in my to-read.
EDIT: I just read that Bob Taylor has died today at 85. :(
Very nice, and I got a couple of book references I'm already pushing in my to-read.
EDIT: I just read that Bob Taylor has died today at 85. :(
sábado, 1 de abril de 2017
TIL: Amazon Nat Gateway drops your connections after 5 mins idle
Yes, after many hours of head scratching, I found out that if you're inside an amazon VPC, and use a NAT gateway or a NAT instance as your internet gateway, silent connections for more than 5 minutes will be dropped, or, even "better", just silenced, but you won't notice anything, just silence.
For long streaming connections going 'mute' for maintenance, you won't recover automatically.
For long streaming connections going 'mute' for maintenance, you won't recover automatically.
WOW: Is it possible that in 2024, I just hit this again?
I found the info here of what I hit back on 2017:
https://repost.aws/knowledge-center/vpc-troubleshoot-nat-gateway-connection
https://docs.aws.amazon.com/vpc/latest/userguide/nat-gateway-troubleshooting.html
text:
IdleTimeoutCount error to release capacity
If a connection that uses a NAT gateway is idle for 350 seconds or more, then the connection times out. You also will see a spike on the IdleTimeoutCount metric. When a connection times out, a NAT gateway returns an RST packet to any resources behind the NAT gateway that attempt to continue the connection. The NAT gateway doesn't send a FIN packet.
To resolve or work around the IdleTimeoutCount error, complete the following tasks:
- Use the IdleTimeoutCount metric in Amazon CloudWatch to monitor for increases in idle connections. Make sure that you configure CloudWatch Contributor Insights to get visibility on the top contributors of clients with processes in the Idle state.
- Close idle connections from clients to release capacity.
- Initiate more traffic over the connection.
- Turn on TCP keepalive on the instance with a value that's less than 350 seconds.
miércoles, 15 de marzo de 2017
Browsing allegro lisp docs inside emacs
While programming, I love to read documentation using helm-dash. I've created quite a few docsets for apps/languages that lacked them in the official repos.
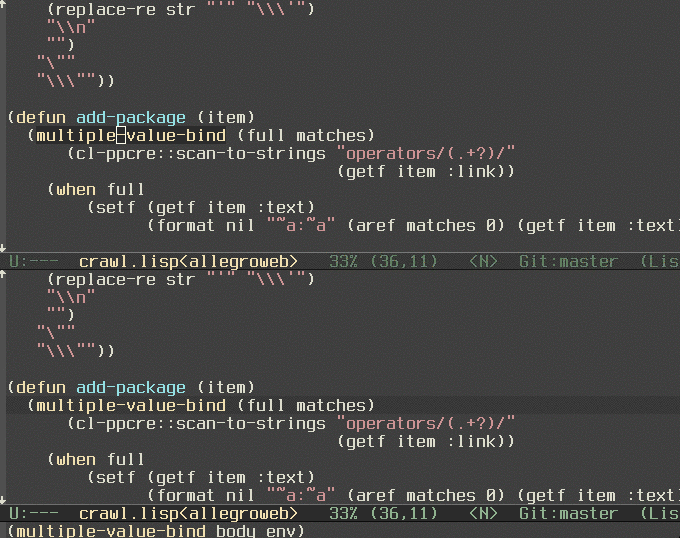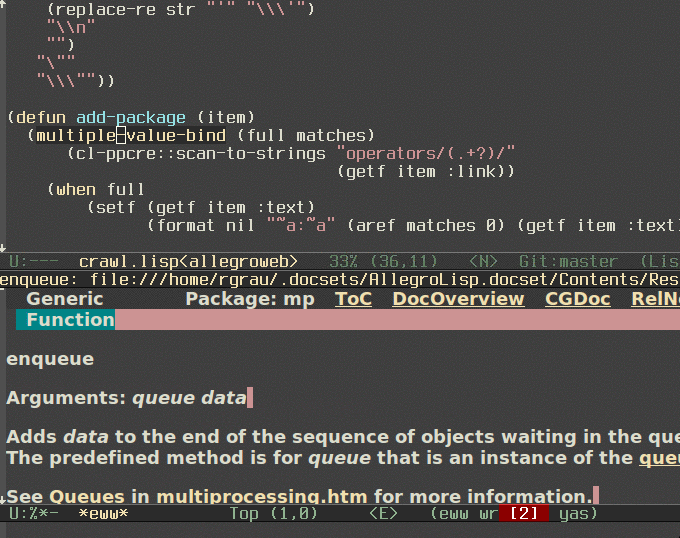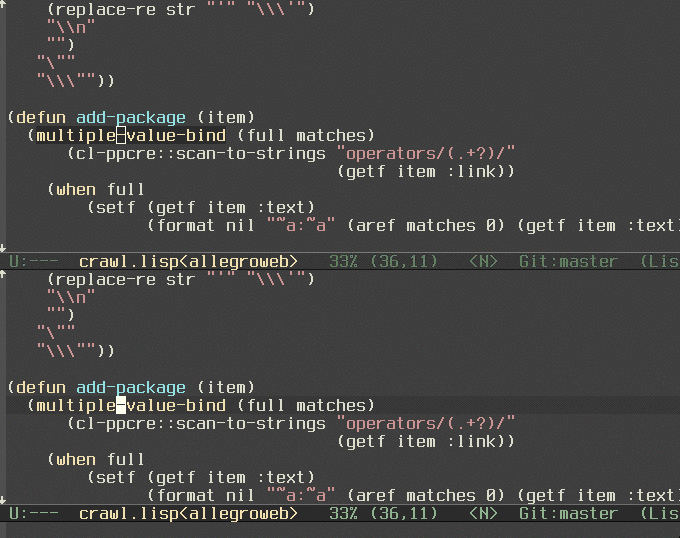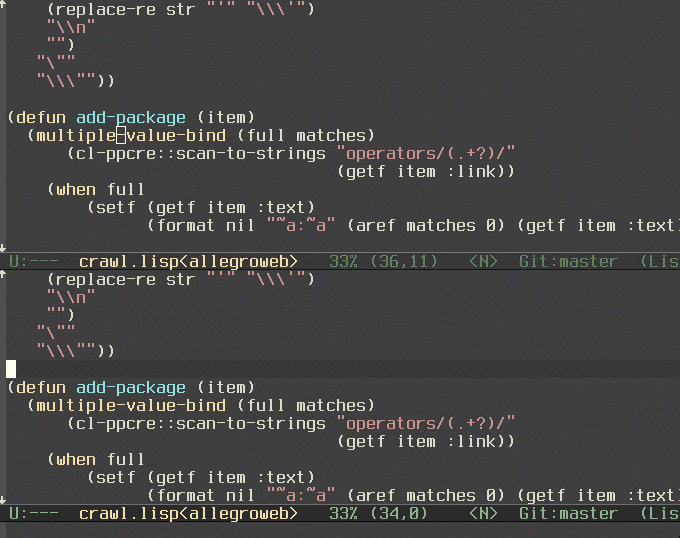
Currently I was using python, common lisp, Picolisp, and Redis, but I felt I was going too often to the franz's Allegro Lisp documentation site. It's nice and loads fast, but it doesn't provide any useful search.
So I created a dash docset for Franz's Allegro Lisp. As usual, it's in my github.
And here's a little gif I recorded to see how does it look.
Currently I was using python, common lisp, Picolisp, and Redis, but I felt I was going too often to the franz's Allegro Lisp documentation site. It's nice and loads fast, but it doesn't provide any useful search.
So I created a dash docset for Franz's Allegro Lisp. As usual, it's in my github.
And here's a little gif I recorded to see how does it look.
martes, 14 de marzo de 2017
git reflog with dates
reflog is this superhero that only appears when it has to save your ass.
A neat thing about it is that it logs everything you do in a given machine. It works locally, none of the reflog is pushed anywhere, and if you 'git clone', your reflog is empty. But...
For us, that are work are doing very far from BlueGreenDeployments, by doing git pull in a server and reloading (in Common Lisp planet you do hot reloads like a boss), this gives a track of when did pulls happen, and so you can find re-imagine the history of deploys, pulls, deploys, fixes.
It's a suboptimal solution, but given it's for free "don't look a gift horse in the mouth".
As usual in the class of git commands that list info, there are lots of formats and customizations. For me, a simple "git reflog --pretty=oneline --date=short" does the job.
A neat thing about it is that it logs everything you do in a given machine. It works locally, none of the reflog is pushed anywhere, and if you 'git clone', your reflog is empty. But...
For us, that are work are doing very far from BlueGreenDeployments, by doing git pull in a server and reloading (in Common Lisp planet you do hot reloads like a boss), this gives a track of when did pulls happen, and so you can find re-imagine the history of deploys, pulls, deploys, fixes.
It's a suboptimal solution, but given it's for free "don't look a gift horse in the mouth".
As usual in the class of git commands that list info, there are lots of formats and customizations. For me, a simple "git reflog --pretty=oneline --date=short" does the job.
domingo, 12 de marzo de 2017
CTMCP finished!
After a big hiatus of 6 months (space for CLtL The unix programming environment, Object-Oriented Programming in Common LISP
,To mock a mockingbird (part of it) , I continued reading Concepts, Techniques, and Models of Computer Programming.
And it's so good I'm gonna put it next to SICP, GEB, HOP and PAIP (when I get around finishing it). Here are some highlights:
Next, I'm reading PoEAA (a bit old and enterprisey but it's Fowler). And I have Beautiful Data (O'Reilly) waiting....
,To mock a mockingbird (part of it) , I continued reading Concepts, Techniques, and Models of Computer Programming.
And it's so good I'm gonna put it next to SICP, GEB, HOP and PAIP (when I get around finishing it). Here are some highlights:
- The book covers a huge spectrum of programming techniques, and ponders lots of variants and different ways of achieving different tasks. It focuses a lot in declarative programming, which comes very natural for extending the model to streams, logic, relational and constraint programming.
- The whole book examples are written in Oz/Mozart, which is a multi-paradigm language with a Prolog-ish syntax which seemed quite odd in the beginning but in the end I learned to like.
- The tone of the book is so unopinionated and so 'formal', that I missed Eva Lu Ator, and Alyssa P. Hacker.
- I had a lovely AHA moment when discovering difference lists. Very useful to understand the paradigm shift of Prolog style programming.
- Concurrency is touched quite heavily, and the explanations on why the different models exist, and when to use what were very useful from a practical perspective. I loved how they introduced Active Objects.
- Explanations of 'well known' concepts like recusion, accumulators, mapcar, transducers, closures, and streams are very nice, and made me remember of the times I discovered them for the very first time.
- Overall, the book is very readable. Clear style and vocab makes it readable in bed.
- There's an introduction to Constraint Programming. Which feels like total magic. I guess it deserves reading a whole book on that to know a bit more about it.
Next, I'm reading PoEAA (a bit old and enterprisey but it's Fowler). And I have Beautiful Data (O'Reilly) waiting....
viernes, 10 de febrero de 2017
Zsh global aliases for command chaining
(The motivation for this post is my recent discovery of oilshell, a very promising new shell. The author has been posting regularly for some time, and he has quite insightful ideas. Some of them I had them too and I didn't know they conformed to some defined concepts (I discovered Bernstein chaining two weeks ago). Whatever.... here it goes, as a way to open more discussion topics)
There's a small zsh trick that is unmatched by any other shell. It's maybe just syntax sugar, but it enables some pretty neat tricks.
The feature is global aliases (or "alias -g").
They are alias substituted anywhere on a line. Global aliases can be used to abbreviate frequently-typed usernames, hostnames, etc.
I think of them as some kind of reader macro, that applies substitutions to strings at read time, so there's no need to substitute a full command by another full command.
Given this ("git last week"), we can use it in different contexts. In this example, the only useful ones that come to my mind are "git log" and "gitk", but to get the feeling of what it does internally, you can 'echo GLWEEK' and you'll get the flags printed. It allows for a lot of composability, and Bernstein chaining because everything concatenates and tries to apply.
If you make aliases expand to pipes (left, right or both), you can make many unix commands compose in a seamless way. Under the hood, you know that the connexion happens through stdin/stdout, but visually it eliminates most of the clutter.
Let's see some examples:
Let's see a few ways we can compose this:
With some training, it's very easy to see that this will copy the last file that matches 'foo' but doesn't match 'bar', or it will open the selected pdf file.
Which works, but it breaks the pipe flow. For that, we can use xargs (as we saw a few posts ago), and we can use, again, another global alias:
now we can do "ls *(mpg|mp4|avi) DM XA mplayer" .
Let's see how to use this one: For the sake of the example, let's pretend we want to know the users that have some process running in my machine.
Of course, this is the same as typing the vanilla commands yourself, but IMO, it makes quite a lot of difference on the experimentation easiness.
There are some more fancy tricks, but we'll leave them for some future post.
The whole point of this is that some features allow for greater composability, and let you build your ad-hoc tools in a much easier way than others. Oilshell has plans to have '{', '}' and '[', ']' as operators, so you can have block like syntax (maybe the semantics of tcl's quoting would be enough?). Anyway, it's great that the shell space is active and there are interesting things happening. I'll keep oil in my radar :)
There's a small zsh trick that is unmatched by any other shell. It's maybe just syntax sugar, but it enables some pretty neat tricks.
The feature is global aliases (or "alias -g").
They are alias substituted anywhere on a line. Global aliases can be used to abbreviate frequently-typed usernames, hostnames, etc.
I think of them as some kind of reader macro, that applies substitutions to strings at read time, so there's no need to substitute a full command by another full command.
alias -g
The simplest case is to make an alias for a bunch of flags for a command you use many times (Also look at zsh globbing to see other examples of 'simple' alias -g).
alias -g GLWEEK=' --since=1.week.ago --author=kidd'
Given this ("git last week"), we can use it in different contexts. In this example, the only useful ones that come to my mind are "git log" and "gitk", but to get the feeling of what it does internally, you can 'echo GLWEEK' and you'll get the flags printed. It allows for a lot of composability, and Bernstein chaining because everything concatenates and tries to apply.
Piping through
Another way to see it is as a way to Forthify your shell a bit more with pipes. This is how I use the feature the most:
If you make aliases expand to pipes (left, right or both), you can make many unix commands compose in a seamless way. Under the hood, you know that the connexion happens through stdin/stdout, but visually it eliminates most of the clutter.
Let's see some examples:
alias -g T='| tail'
alias -g T1='T -1'
alias -g X='| xclip '
alias -g G='| grep '
alias -g GV='| grep -v '
alias -g DM='| dmenu '
Let's see a few ways we can compose this:
ls -ltr G foo GV bar T1 X
evince $(ls *pdf DM)
With some training, it's very easy to see that this will copy the last file that matches 'foo' but doesn't match 'bar', or it will open the selected pdf file.
XARGS
There are some commands that do not accept arguments from stdin, but they require them to be as command line arguments. in those cases, one starts doing things like:
mplayer $(ls *(mpg|mp4|avi) DM )
Which works, but it breaks the pipe flow. For that, we can use xargs (as we saw a few posts ago), and we can use, again, another global alias:
alias -g XA='| xargs '
now we can do "ls *(mpg|mp4|avi) DM XA mplayer" .
FUNCTIONS
Here's an example of a uniq function on steroids. it accepts a field number to uniquify, and the rows do not have to be sorted to work.
function uc () {
awk -F" " "!_[\$$1]++"
}
alias -g UC=' | uc '
alias -g P1='| awk "{print \$1}"'
Let's see how to use this one: For the sake of the example, let's pretend we want to know the users that have some process running in my machine.
ps -axuf GV USER UC 1 P1
Of course, this is the same as typing the vanilla commands yourself, but IMO, it makes quite a lot of difference on the experimentation easiness.
There are some more fancy tricks, but we'll leave them for some future post.
The whole point of this is that some features allow for greater composability, and let you build your ad-hoc tools in a much easier way than others. Oilshell has plans to have '{', '}' and '[', ']' as operators, so you can have block like syntax (maybe the semantics of tcl's quoting would be enough?). Anyway, it's great that the shell space is active and there are interesting things happening. I'll keep oil in my radar :)
miércoles, 8 de febrero de 2017
Henry G Baker's papers
I was rereading "Out of the tarpit" paper, and by the end of it I noticed they reference a paper from Henry Baker: "Equal rights for functional objects or, the more things change, the more they are the same.". The author's name rang a bell, and I decided to explore a bit more.
So, He's the author of a paper I loved to read 3 months ago or so: Pragmatic Parsing in Common Lisp.
The article is an adaptation of Val Schorre's META-II paper to common lisp, leveraging reader macros to create parsers in very few lines of code.
Reading a bit more, I found this other very enjoyable article: Metacircular Semantics for Common Lisp Special Forms . This one takes the approach of metacircular interpreters to explain the behaviour of some common lisp special forms in terms of other common lisp expressions. I love the bottom up approach, and reminds me of "git from the bottom up", or CTMCP's explanations of the extensions to the Oz language.
He wrote lots of articles related to Lisp to different degrees, but most of them (the ones I skimmed) are written in a very clear language (no pun intended), and quite fun and enlightening reads.
So, He's the author of a paper I loved to read 3 months ago or so: Pragmatic Parsing in Common Lisp.
The article is an adaptation of Val Schorre's META-II paper to common lisp, leveraging reader macros to create parsers in very few lines of code.
Reading a bit more, I found this other very enjoyable article: Metacircular Semantics for Common Lisp Special Forms . This one takes the approach of metacircular interpreters to explain the behaviour of some common lisp special forms in terms of other common lisp expressions. I love the bottom up approach, and reminds me of "git from the bottom up", or CTMCP's explanations of the extensions to the Oz language.
He wrote lots of articles related to Lisp to different degrees, but most of them (the ones I skimmed) are written in a very clear language (no pun intended), and quite fun and enlightening reads.
domingo, 22 de enero de 2017
Autocomplete erc nicks with @ sign (for slack)
This is a very quick hack for something I've wanted for some time. I'm using slack through their IRC gateway. That allows me to use erc, yasnippets, bug-reference-mode, and whatnot.
The few things that annoy me of that interface is that to ping users, in slack you are expected to prepend the nick with an at sign. That makes autocompletion kinda useless because, as this redditor explains , it's a pain in the ass to type the nick, autocomplete, go back, add the @ sign, and move forward.
I haven't found a way to solve this in an elegant way, but as a hack, I could add tihs advice functions that will understand @nick as well as 'nick' when autocompleting. I'd love to be able to just type the name and the autocompletion framework fill the '@' sign itself, but I couldn't find it, so I'll try this approach I got so far and see if it works well enough for me.
I hope it's useful for some of you, dear emacslackers :)
The few things that annoy me of that interface is that to ping users, in slack you are expected to prepend the nick with an at sign. That makes autocompletion kinda useless because, as this redditor explains , it's a pain in the ass to type the nick, autocomplete, go back, add the @ sign, and move forward.
I haven't found a way to solve this in an elegant way, but as a hack, I could add tihs advice functions that will understand @nick as well as 'nick' when autocompleting. I'd love to be able to just type the name and the autocompletion framework fill the '@' sign itself, but I couldn't find it, so I'll try this approach I got so far and see if it works well enough for me.
I hope it's useful for some of you, dear emacslackers :)
sábado, 21 de enero de 2017
using xargs to parallelize command line
Did you know that xargs can spawn multiple processes to execute the commands it gets?
It's the poor man's gnu parallel (very poor).
Well, I've been dabbling quite a bit with shell scripts lately and I've come to this balance of using shellscripts for simple (or not so simple) tasks. It's a mix of suckless and Taco Bell programming....
Well, the problem at point was to create many connections to some api endpoints. The endpoints would be serving data in a streamming fashion (think twitter hose). My idea would be to spawn several curls to a "circular" list of urls.
I thought about wrk (because lua), vegeta or siege, but I'm not sure how they would cope with 'persistent' connections, so I tried my luck with plain curl and bash.
It's funny how you can solve some issues in bash with so few lines of code. I don't have stats, or anything, but the only thing I wanted, that was to generate traffic can be done in plain simple shellscripting.
Things I learned:
- ${variable:-"default-value"} is great
- doing arithmetic in bash is next to impossible.
- xargs can spawn multiple processes, and you can control the number, so you can use the number as an upper limit.
- while true + timeout are a very nice combo when you want to generate any kind of 'ticking' or 'movement' on the loop.
Here's the script:
Well, I've been dabbling quite a bit with shell scripts lately and I've come to this balance of using shellscripts for simple (or not so simple) tasks. It's a mix of suckless and Taco Bell programming....
Well, the problem at point was to create many connections to some api endpoints. The endpoints would be serving data in a streamming fashion (think twitter hose). My idea would be to spawn several curls to a "circular" list of urls.
I thought about wrk (because lua), vegeta or siege, but I'm not sure how they would cope with 'persistent' connections, so I tried my luck with plain curl and bash.
It's funny how you can solve some issues in bash with so few lines of code. I don't have stats, or anything, but the only thing I wanted, that was to generate traffic can be done in plain simple shellscripting.
Things I learned:
- ${variable:-"default-value"} is great
- doing arithmetic in bash is next to impossible.
- xargs can spawn multiple processes, and you can control the number, so you can use the number as an upper limit.
- while true + timeout are a very nice combo when you want to generate any kind of 'ticking' or 'movement' on the loop.
Here's the script:
jueves, 19 de enero de 2017
git contribution spans (emacs case study)
Let's play a little, just for the fun of it, and to gather some metainformation about a codebase.
I sometimes would like to find out the commit spans of the different authors. I may not care about the number of commits, but only first and last. This info may be useful to know if a repo has most long time commiters or the majority of contributors are one-off, or one-feature-and-forget.
First we'll sharpen a bit our unix chainsaw:
Here's a little helper that has proven to be very useful. It's similar to uniq, but you don't need to sort first, and also it accepts a parameter meaning the column you want to be unique. (Unique by Column)
And then, you only have to look at man git-log to find out you can reverse the order of the logs, so you can track the first and the last appearence of each commiter.
Here is the output file. it has some spurious parsing errors, but I think it still shows how powerful insights we can get with just a bit of bash, man and pipelines.
Just by chance, the day after I tried this, I discovered git-quick-stats, which is a utility tool to get simple stats out of a git repo. It's great that I could add the same functionality there too via a Pull Request :).
Big thanks to every one of the commiters in emacs, being long or short span and amount of code contributed. Thanks to y'all
I sometimes would like to find out the commit spans of the different authors. I may not care about the number of commits, but only first and last. This info may be useful to know if a repo has most long time commiters or the majority of contributors are one-off, or one-feature-and-forget.
First we'll sharpen a bit our unix chainsaw:
Here's a little helper that has proven to be very useful. It's similar to uniq, but you don't need to sort first, and also it accepts a parameter meaning the column you want to be unique. (Unique by Column)
function uc () {
awk -F" " "!_[\$$1]++"
}
And then, you only have to look at man git-log to find out you can reverse the order of the logs, so you can track the first and the last appearence of each commiter.
git log --format='%aE %ai' | uc 1 | sort >/tmp/last git log --reverse --format='%aE %ai -> ' | uc 1 | sort >/tmp/first paste /tmp/first /tmp/last > /tmp/spans.txt
Here is the output file. it has some spurious parsing errors, but I think it still shows how powerful insights we can get with just a bit of bash, man and pipelines.
Just by chance, the day after I tried this, I discovered git-quick-stats, which is a utility tool to get simple stats out of a git repo. It's great that I could add the same functionality there too via a Pull Request :).
Big thanks to every one of the commiters in emacs, being long or short span and amount of code contributed. Thanks to y'all
gnu parallel as a queuing system
This post is about a gnu parallel, a tool I recently discovered, and I'm starting to use a bit more every day.
At its core, it's a command to multiple commands in parallel, but it has many many different options to customize how the paralelization is done, notifications, and other configs. Take a look at the official tutorial or the man page, which contain a wealth of info and examples.
First of all, we notice the pattern of the links:
We notice the pattern, right? Let's craft some generator for the filenames.
After we generated the file, we're going to run the command in the following way:
this makes parallel run one after the other, and just putting the outputs of each job in a tmux tab.
So, here's the command to use this tool as a queuing system.
Then, add lines to the joblist for them to be executed. It's a very easy plumbing task:
tail -f works as our event loop, waiting for new tasks to come, and it will pass the tasks to parallel, that will apply the job contention depending on the number of jobs you configure it to run in parallel.
I've just scratched the surface of what parallel is able to do. Do some searching around, and take a look at the man and tutorial to get a grasp of what this amazing gnu tool is able to do. Taco Bell programming at its best!
At its core, it's a command to multiple commands in parallel, but it has many many different options to customize how the paralelization is done, notifications, and other configs. Take a look at the official tutorial or the man page, which contain a wealth of info and examples.
Let's get SICP videos
The use case I have today is to use it as a simple queuing system. I just want processes to start when I have a new job for them. The task at hand is to download all sicp lectures, at one download at a time (don't want to hog the network).First of all, we notice the pattern of the links:
- http://www.archive.org/download/MIT_Structure_of_Computer_Programs_1986/lec1a.mp4
- http://www.archive.org/download/MIT_Structure_of_Computer_Programs_1986/lec1b.mp4
- http://www.archive.org/download/MIT_Structure_of_Computer_Programs_1986/lec2a.mp4
- http://www.archive.org/download/MIT_Structure_of_Computer_Programs_1986/lec2b.mp4
We notice the pattern, right? Let's craft some generator for the filenames.
perl -e 'for(1..15){for $i (('a','b')){print "wget http://www.archive.org/download/MIT_Structure_of_Computer_Programs_1986/lec$_$i.mp4\n"}}' >sicp.list
After we generated the file, we're going to run the command in the following way:
cat sicp.lisp | parallel -j1 --tmux
this makes parallel run one after the other, and just putting the outputs of each job in a tmux tab.
B, b, but.... what's the point of all this?
Ok, we didn't use parallel for anything useful, we could have run the list as a shellscript, and be happy. The idea is that we can use this simple mechanism to treat the file as a job queue, that waits for new incomming jobs and then processes them. Beware, it has very little logging, and you can't do very sophisticated error recovery (see --resume-failed), so it's NOT a replacement for resque/sidekiq/etc... In fact, I'd love to see something like a suckless queuing system based on parallel and bash.So, here's the command to use this tool as a queuing system.
touch joblist; tail -f joblist | parallel --tmux
Then, add lines to the joblist for them to be executed. It's a very easy plumbing task:
echo "sleep 10" >joblist
tail -f works as our event loop, waiting for new tasks to come, and it will pass the tasks to parallel, that will apply the job contention depending on the number of jobs you configure it to run in parallel.
I've just scratched the surface of what parallel is able to do. Do some searching around, and take a look at the man and tutorial to get a grasp of what this amazing gnu tool is able to do. Taco Bell programming at its best!
References
Here I'm pasting some useful refs (appart from the ones already mentioned).
Suscribirse a:
Entradas (Atom)

